
Ahoy, tech enthusiasts and digital buccaneers! Today, we're embarking on a thrilling adventure across the vast oceans of artificial intelligence with our trusty ship, the "Mistral-Docker-API." So, grab your digital compasses and set sail with me as we navigate through the exciting world of deploying AI models using Docker, and eventually docking at the shores of Google Cloud Run.
The Treasure Map: Setting Up Your Ship
Before we hoist the sails, every good pirate needs a map. In our case, it's the README.MD of the mistral-docker-api. This map doesn't lead to buried treasure, but to something even better: deploying the GGUF Mistral model as a container using Docker.
First things first, you need to download the model and store it in your models/ folder. Imagine this model as the secret code to an ancient treasure. You can find this precious artifact at Hugging Face, a place even more mysterious than the Bermuda Triangle!
Once you've got your model, named something like models/mistral-7b-instruct-v0.2.Q4_K_M.gguf, you're ready to build your Docker image. Think of this as building your ship. Run docker build . --tag mistral-api in your command line, and voilà, your ship is ready!
But hey, if you're feeling a bit lazy, like a pirate lounging on the deck, you can just pull the pre-built image using docker pull cloudcodeai/mistral-quantized-api. Then, run it with a simple command: docker run -p 8000:8000 mistral-api. And there you go, your ship is not only built but also sailing!
Here is the link to the treasure map if you are feeling adventurous: 🏴☠️ Treasure
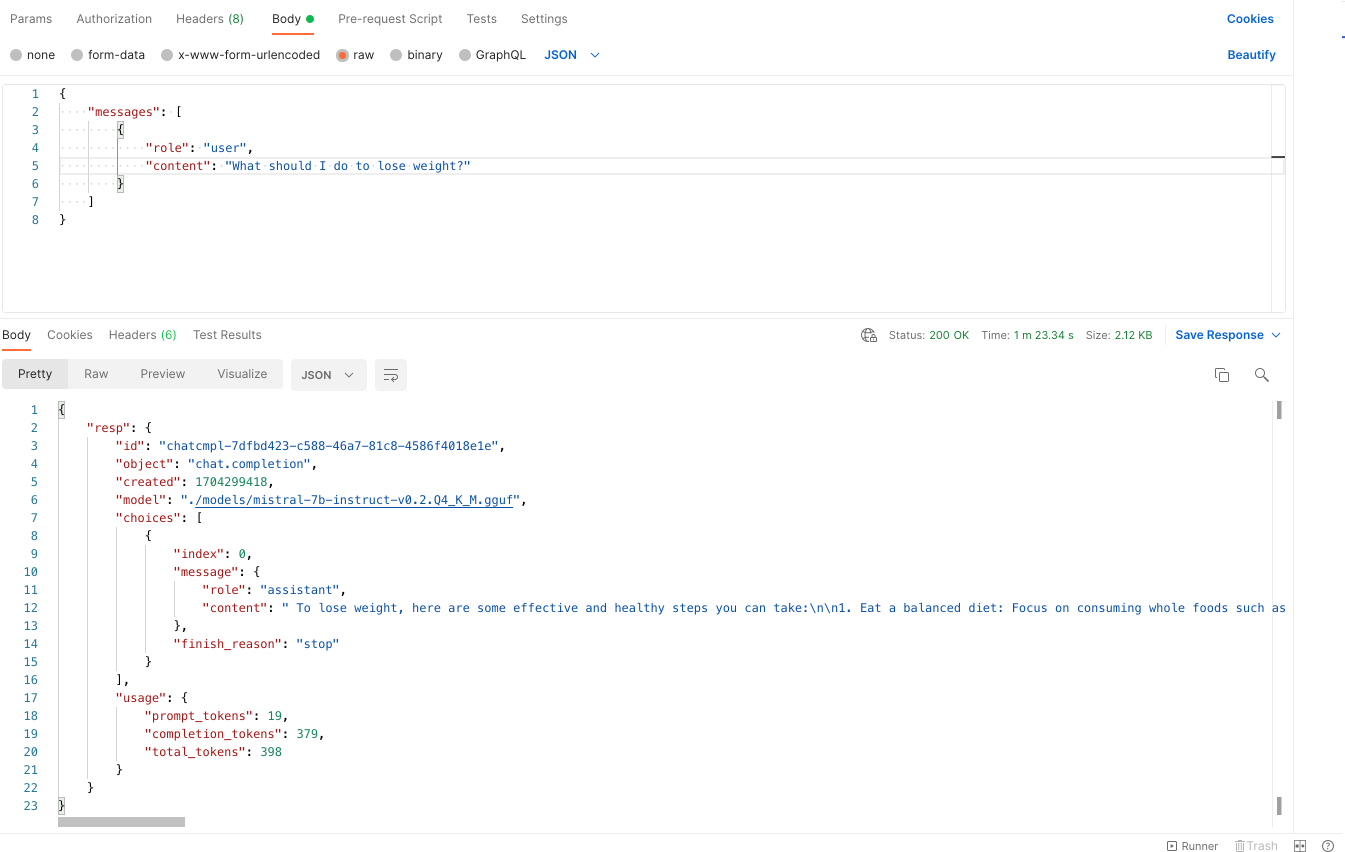
The Mystical Inference at the /infer Endpoint
Now, let's talk about the magic happening at the /infer endpoint. It's like finding a talking parrot that can answer any question. You send a message asking, "What's the value of pi?" and the parrot squawks back with an answer so detailed, you'd think it swallowed a math textbook!
But this isn't just any parrot; it's a customizable one! You can tweak its responses with parameters like temperature, top_p, and even max_tokens. It's like teaching your parrot new tricks to impress your pirate friends.
Anchoring at Google Cloud Run
Now, let's talk about docking this ship at Google Cloud Run. Why? Because even pirates need a break from the high seas, and Google Cloud Run is like the perfect tropical island for our container ship.
-
Prepare Your Container Image: Make sure your Docker image is ready and tested. It's like making sure your ship has no leaks.
-
Push to Container Registry: Upload your Docker image to Google Container Registry. It's like storing your ship in a safe harbor. If you are lost, worry not, here is our new north start Perplexity AI to guide you!
-
Create a New Service in Cloud Run: Navigate to Google Cloud Run and create a new service. Choose the image you just pushed to the registry. It's like telling the harbor master where your ship is.
-
Configure Your Service: Set memory as 32GB, CPU as 8v, and other settings as shown in the map below. It's like stocking up on supplies and making sure your cannons are ready for action.
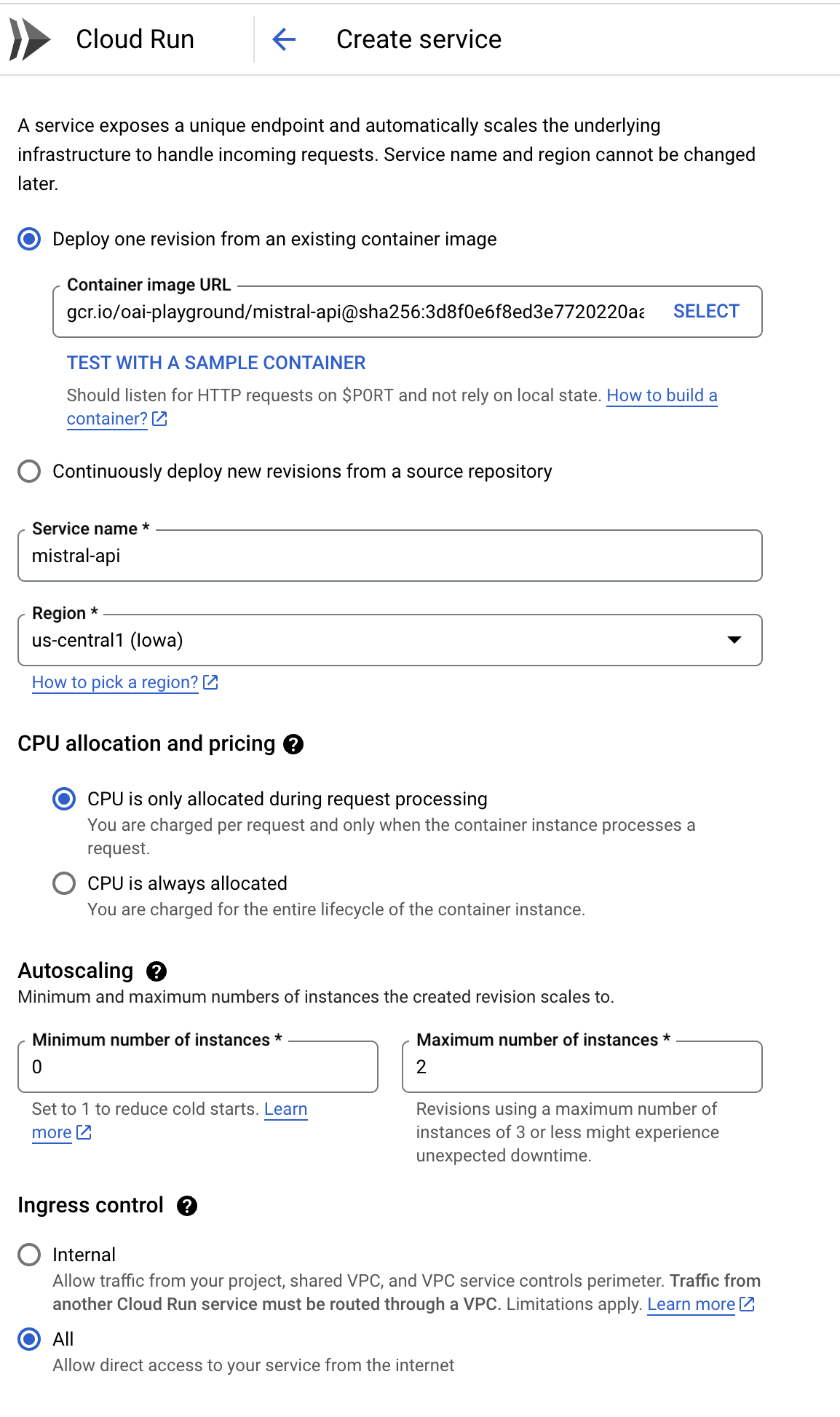
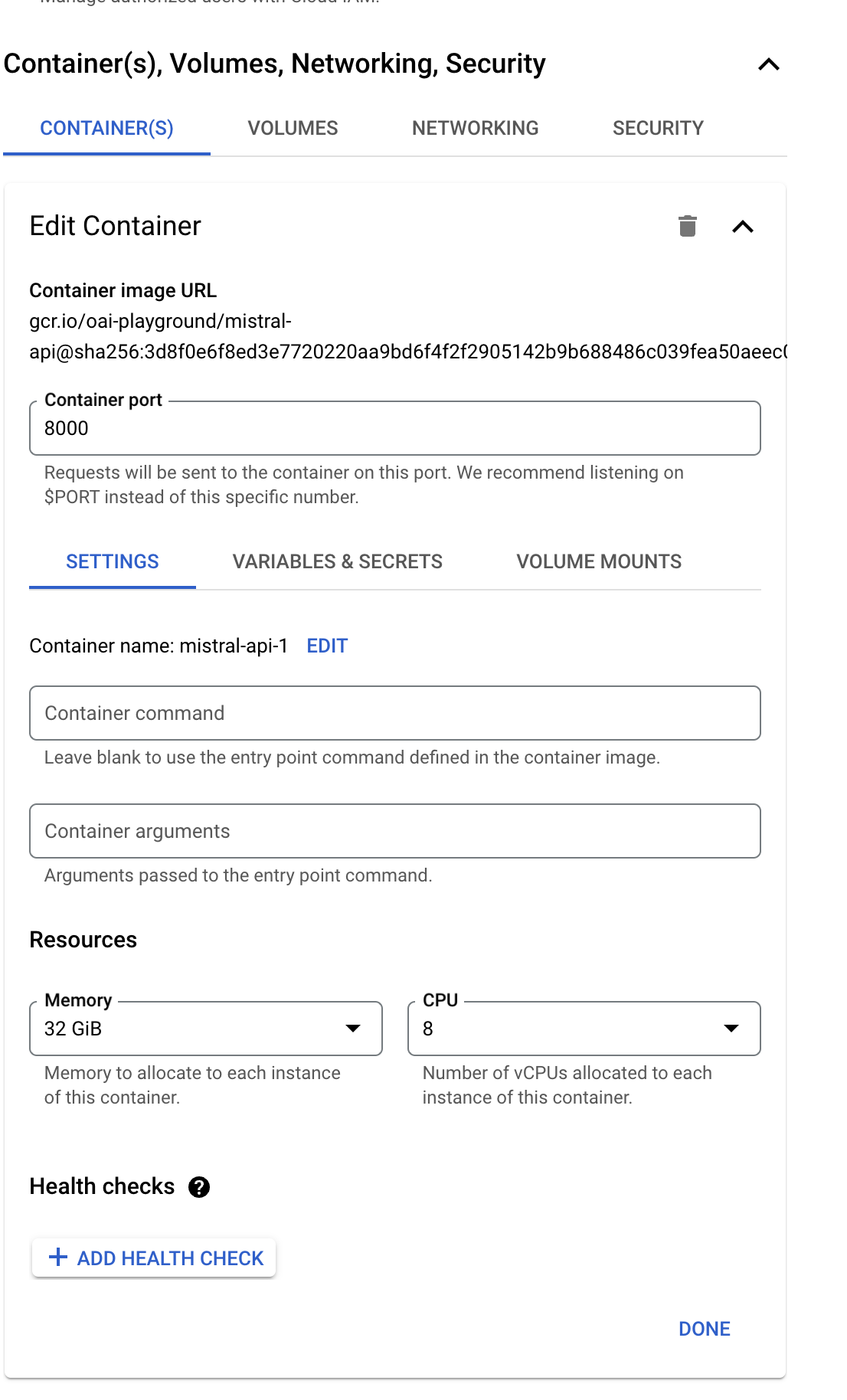
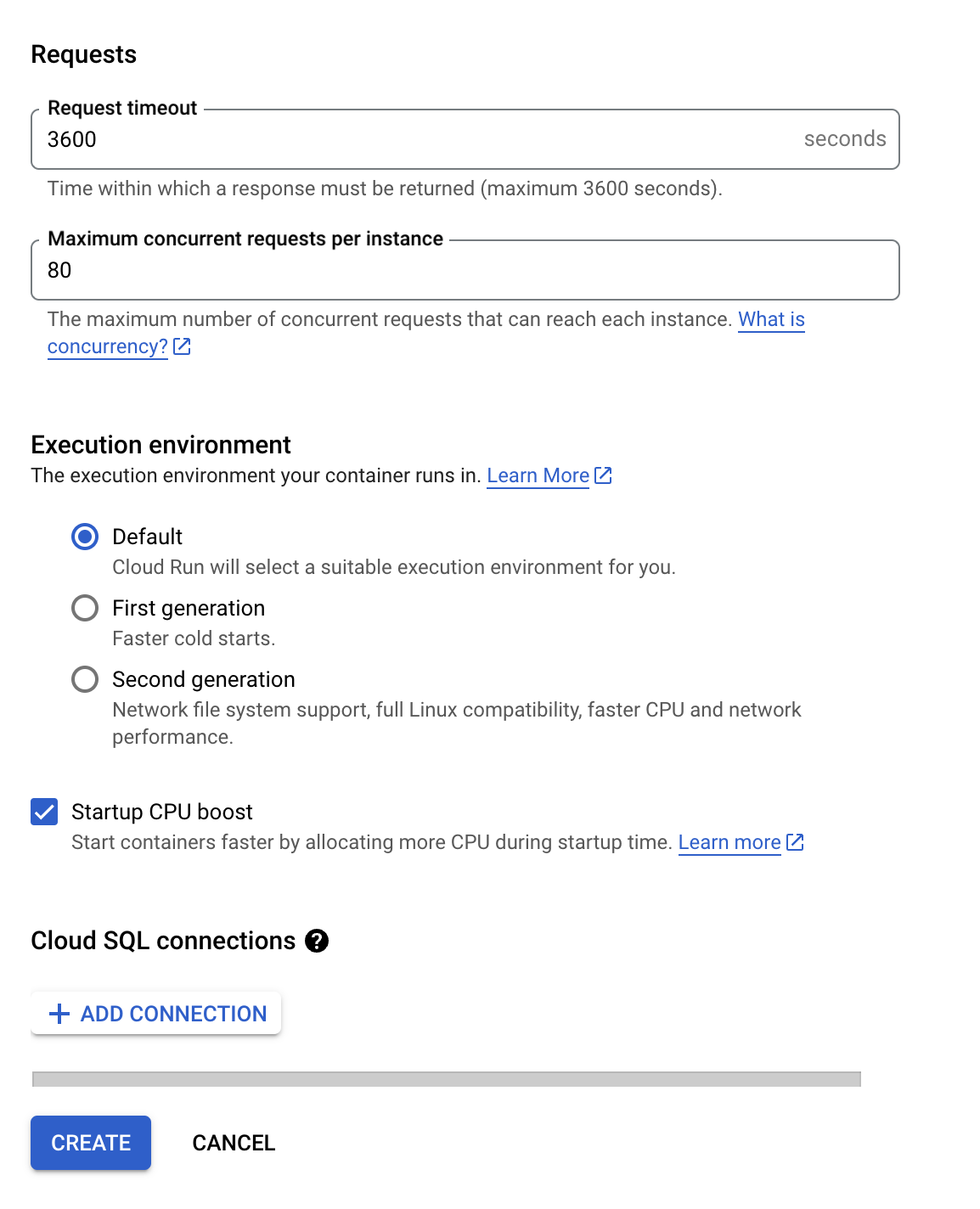
-
Deploy and Conquer: Hit deploy and watch as your service goes live. Your API is now sailing on the high clouds, ready to answer queries from all over the world.
-
Access Your Service: Use the URL provided by Cloud Run to access your service. It's like having a secret map to your hidden cove.
And there you have it, mateys! You've successfully navigated the treacherous waters of AI and Docker, and found a safe harbor in Google Cloud Run. Now, go forth and explore this new world, full of possibilities and adventures. And remember, in the vast sea of technology, there's always more to discover and conquer. Arrr! 🏴☠️💻🌊
View From the Analytical Lighthouse
Captain, its an miracle but a slow one!
Our mistral api ship is responding to us but being tiny in such a vast ocean, its responses are pretty slow.
During the first call, it takes 5-6 mins to reply to our input and provide a 400 token long response.
But once its on, it take 1-2 mins to response to our other calls. Hera are the samples.
Cold Start
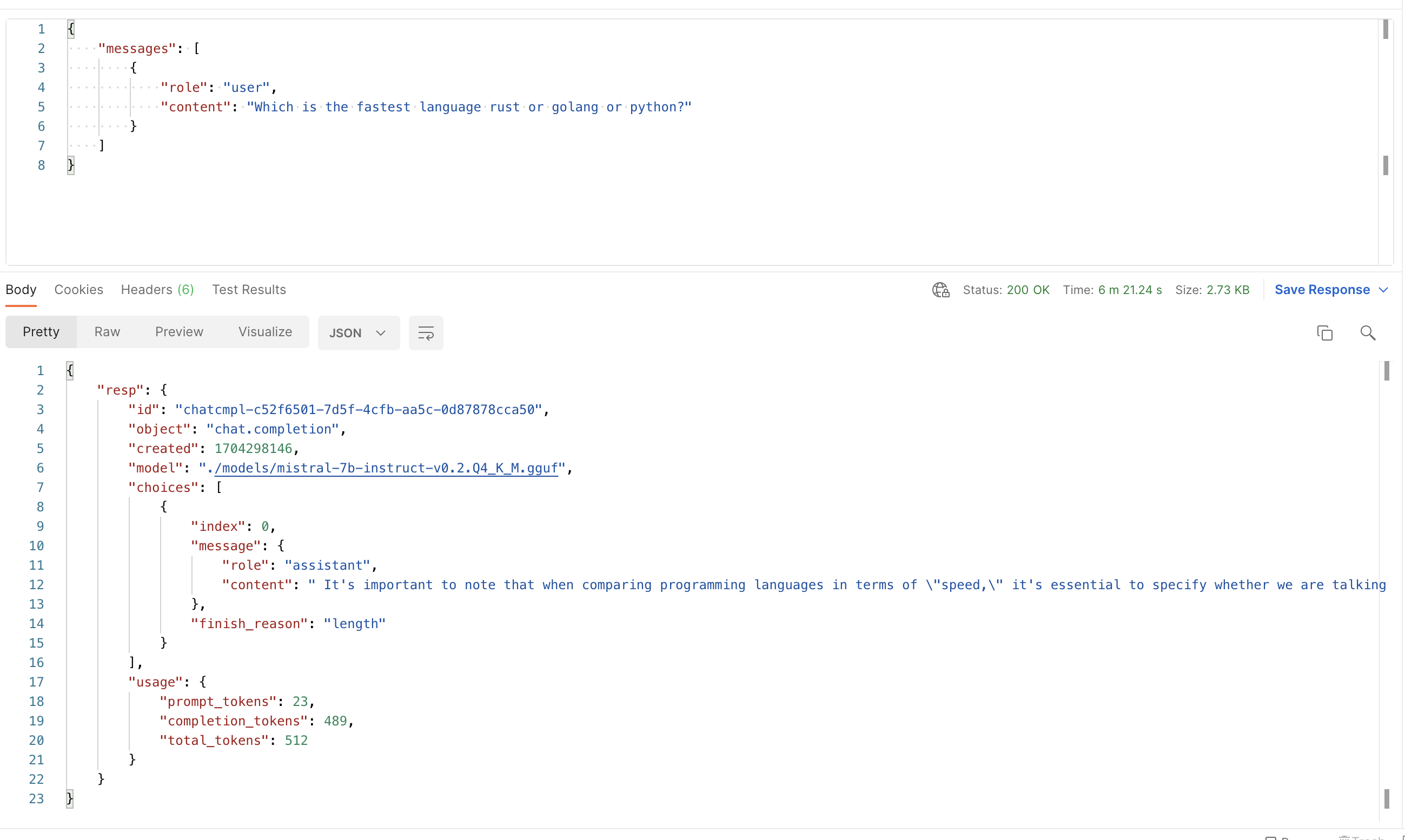
Warm Start
Future Plans
- We plan to make our ship more lean and efficient and make it respond faster.
- We want to experiment whats the idea resources to provide so that we can sail multiple ships in the ocean.
